菜单导航
一、变量在计算中的内存分配
1、变量为什么要有类型?
每种类型占用内存空间不一样,比如char占一个字节,short占2个字节,int占4个字节,double占8个字节
2、只要定义变量,系统就会开辟一块存储空间给变量存储数据;
3、变量地址以字节为最小单位,内存寻址从大到小,也就是所先定义的变量,内存地址越大;
变量的地址就是变量所占的存储空间最小的字节地址。
举例验证:
int num0 = 518; //4个字节 short num1 = 12; //2个字节 char c1 = 'a'; //1个字节 printf("num0地址:%p, num1地址:%p, c2地址:%p , a: %d\n", &num0, &num1, &c1, c1); /** 地址打印结果:可以看出越先定义的变量地址越大,地址是分配从大到小进行;变量的地址是该变量所占存储空间的最小的字节地址 num0地址:0x7fff5fbff72c, num1地址:0x7fff5fbff72a, c2地址:0x7fff5fbff729 */ 使用excel画图表说明这个地址分配:

int num0 = 518; 占用四个字节,我们把这四个字节的每个字节中的值打印出来,印证一下:
//打印出int类型的变量num0每个字节中的值来 int num0 = 518; //4个字节 char *c = &num0; for (int i = 0; i < sizeof(num0); i++) { int result = c[i]; printf("i=%i, result: %i \n", i, result); } /** 打印结果:证明了num0的地址分配,以及num0的每个字节中存储的二进制值 i=0, result: 6 i=1, result: 2 i=2, result: 0 i=3, result: 0 */
二、字符char类型的操作
char类型占用一个字节,取值范围0000 0000 ~ 0111 1111 --> 0~127
#includechar getCapitalChar(char lowercase); //声明函数int main(){ printf("....test char....\n"); size_t byteCount = sizeof(char); //char类型占用字节个数 printf("char数据类型占用字节个数:%zu\n", byteCount); //打印结果:char数据类型占用字节个数:1 char c0 = getCapitalChar('z'); char c1 = getCapitalChar('d'); char c2 = getCapitalChar('y'); char c3 = getCapitalChar('H'); char c4 = getCapitalChar('*'); printf("c0: %c, c1: %c, c2: %c, c3: %c, c4: %c \n", c0, c1, c2, c3, c4); //打印结果:c0: Z, c1: D, c2: Y, c3: H, c4: * //char类型的取值范围为0-127,一旦超过其取值范围,则显示不正常了 char c5 = 0; char c6 = 127; char c7 = 128; char c8 = -128; char c9 = 300; char c10 = 44; printf("c5: %d, c6: %d, c7: %d, c8: %d ,c9: %d, c10: %d \n", c5, c6, c7, c8, c9, c10); /** 打印结果为: c5: 0, c6: 127, c7: -128, c8: -128 ,c9: 44, c10: 44 为什么c7 = 128 和c8 = -128打印%d显示的结果一样 ? c9 = 300 和 c10 = 44打印%d显示的结果一样 ? 分析:char占用一个字节,取值范围为0000 0000 ~ 0111 1111 128 的二进制为:1000 0000 , 赋值给char,最高位1既变成了符号位,还参与了计算 300 的二进制为:1 0010 1100,赋值给char, 取后面8位即:0010 1100 == 32 + 8 + 4 == 44 */ printf("\n"); return 0;}/** 定义函数:将小写字母转成大写 */char getCapitalChar(char lowercase){ int bet = 'A' - 'a'; //大写字母A和小写字母a的差 if (lowercase + bet >= 'A' && lowercase + bet <= 'Z'){ return lowercase + bet; } return lowercase;}
三、整型数据类型
整型数据类型在内存中占用字节和系统有关,64位系统和32系统占用字节可能会不一样
/** 测试用整型数据类型占用字节 short == short int --> 2个字节 --> %i / %d long == long int --> 64位8个字节,32位4个字节 --> %li / %ld long long == long long int --> 8个字节 --> %lli / %lld*/size_t size1 = sizeof(short), size2 = sizeof(short int), size3 = sizeof(int);size_t size4 = sizeof(long), size5 = sizeof(long int), size6 = sizeof(long long);size_t size7 = sizeof(long long int); printf("size1: %zu, size2: %zu, size3: %zu, size4: %zu, size5: %zu, size6: %zu, size7: %zu \n", size1, size2, size3, size4, size5, size6, size7); 在64位架构和32位架构打印结果一样:
//64位架构:size1: 2, size2: 2, size3: 4, size4: 8, size5: 8, size6: 8, size7: 8//32位架构:size1: 2, size2: 2, size3: 4, size4: 4, size5: 4, size6: 8, size7: 8
切换应用程序所处架构截图
四、数组操作
//先定义个数组不初始化,数组里面元素默认值为0 int arr[3]; printf("arr[0]: %d, arr[1]: %d, arr[2]: %d \n", arr[0], arr[1], arr[2]); //打印结果:arr[0]: 0, arr[1]: 0, arr[2]: 0 //再初始化数组里面的元素 arr[0] = 88, arr[1] = 99; printf("arr[0]: %d, arr[1]: %d, arr[2]: %d \n", arr[0], arr[1], arr[2]); //打印结果:arr[0]: 88, arr[1]: 99, arr[2]: 0 //定义数组的时候就进行初始化 int arr2[3] = { 22, 33}; //只初始化两个元素 printf("arr2[0]: %d, arr2[1]: %d, arr2[2]: %d \n", arr2[0], arr2[1], arr2[2]); //打印结果:arr2[0]: 22, arr2[1]: 33, arr2[2]: 0 //定义数组时的元素个数用变量代替,元素的初始值是脏数据 int tmp = 3; int arr3[tmp]; //只能定义,如果直接给数组定义且赋值,就会报错:arr3[tmp] = {1,2}; //这种写法编译失败 printf("arr3[0]: %d, arr3[1]: %d, arr[2]: %d \n", arr3[0], arr3[1], arr3[2]); //打印结果:arr3[0]: 1606416240, arr3[1]: 32767, arr[2]: 3546 //数组的遍历 int arr4[5] = { 11, 22, 33}; size_t allBytes = sizeof(arr4); //数组所占总字节 size_t intBytes = sizeof(arr4[0]); //第一个元素占用字节 size_t arrCount = allBytes/intBytes; //数组个数 printf("allBytes: %zu, intBytes: %zu, arrCount: %zu \n", allBytes, intBytes, arrCount); for (int i = 0; i < arrCount; i++) { printf("arr4[%d] = %d \n", i, arr4[i]); } /** 打印日志: allBytes: 20, intBytes: 4, arrCount: 5 arr4[0] = 11 arr4[1] = 22 arr4[2] = 33 arr4[3] = 0 arr4[4] = 0 */
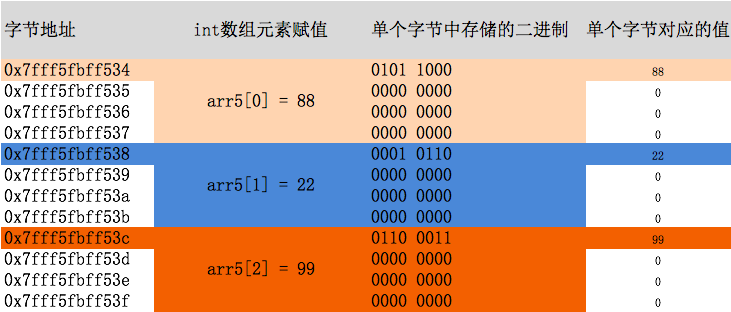
数组中元素地址分配分析
//数组地址分配:数组名就是数组中第一个元素的地址,越后面的元素地址越大 int arr5[3] = { 88, 22, 99}; printf("arr5地址:%p \n", arr5); printf("arr5[0]地址:%p \n", &arr5[0]); printf("arr5[1]地址:%p \n", &arr5[1]); printf("arr5[2]地址:%p \n", &arr5[2]); /** 打印结果:说明了数组 arr5地址:0x7fff5fbff534 arr5[0]地址:0x7fff5fbff534 arr5[1]地址:0x7fff5fbff538 arr5[2]地址:0x7fff5fbff53c */ excel做图表分析:
五、数组越界造成的访问不属于自己的内存空间
//演示数组越界,c语言中没有处理数组越界的情况, //一旦出现数组越界,即访问了没有分配给自己的存储空间,容易引起数据混乱 char cArr1[2] = { 8, 9}; char cArr2[3] = { 88, 22, 99}; printf("cArr1地址:%p, cArr2地址:%p \n", cArr1, cArr2); printf("cArr1[0]: %d, cArr1[1]: %d \n", cArr1[0], cArr1[1]); printf("cArr2[0]: %d, cArr2[1]: %d, cArr2[2]: %d \n", cArr2[0], cArr2[1], cArr2[2]); /** 打印结果: cArr1地址:0x7fff5fbff4fa, cArr2地址:0x7fff5fbff4f7 cArr1[0]: 8, cArr1[1]: 9 cArr2[0]: 88, cArr2[1]: 22, cArr2[2]: 99 */ cArr2[3] = 122; //数组越界,访问了不属于数组cArr2中的内存空间 printf("cArr2[3]: %d, cArr1[0]: %d, cArr[2]: %d, cArr2[0]: %d, cArr2[2]: %d \n", cArr2[3], cArr1[0], cArr1[1], cArr2[0], cArr2[2]); /** 打印结果: cArr2[3]: 122, cArr1[0]: 122, cArr[2]: 9, cArr2[0]: 88, cArr2[2]: 99 问:为什么cArr2[3]的值和cArr1[0]的值一样?cArr2[3]数组越界实际上访问的内存空间是cArr1[0]元素的地址 */ excel图标分析:

给cArr2[3]元素赋值,实际上是数组越界,访问的内存空间是cArr1[0]元素,相当于是给cArr1[0]元素赋值
六、引用数据类型和基本数据类型,形参和实参
/** // 如果形参是基本数据类型,在函数中修改形参的值不会影响到外面的值 // 如果形参是数组,那么在函数中修改形参的值,会影响实参的值 */#include// 基本数据类型作为函数的参数是值传递// 如果形参是基本数据类型,在函数中修改形参的值不会影响到外面的值void change(int value){ printf("change函数中参数value地址:%p \n", &value); value = 55;}// 注意:数组名作为函数的参数传递,是传递的数组的地址// 因为数组名就是数组的地址 &number = &number[0] = number// 注意: 如果数组作为函数的形参,元素的个数可以省略// 如果形参是数组,那么在函数中修改形参的值,会影响实参的值// void chang2(int value[2])void change2(int value[]){ printf("change2函数中value[0]地址:%p \n", &value[0]); value[0] = 88;}int main(){ int number = 10; printf("number地址:%p \n", &number); change(number); printf("number = %i\n",number); /** 打印结果: number地址:0x7fff5fbff758 change函数中参数value地址:0x7fff5fbff72c number = 10 */ int nums[2] = { 1,5}; printf("nums[0]地址:%p\n", &nums[0]); change2(nums); // 相当于传递了数组的地址 printf("nums[0] = %i\n",nums[0]); /** 打印结果: nums[0]地址:0x7fff5fbff760 change2函数中value[0]地址:0x7fff5fbff760 nums[0] = 88 */ nums[0] = 15; change(nums[0]); printf("nums[0] = %i\n",nums[0]); /** 打印结果 change函数中参数value地址:0x7fff5fbff72c nums[0] = 15 */ return 0;}
七、字符串和字符数组
1、C语言规定,字符串必须以\0结尾(作为字符串的结束符号),所以字符串变量的元素个数比字符数组的元素个数多一个\0;
2、双引号下的字符串默认自动加上了\0; 字符数组需要手动加上\0才能算作是字符串;
3、字符串的本质是数组,\0对应的ASCII码为 0
验证双引号字符串默认自动加上\0
char str[] = "bky"; // 字符串变量 b k y \0 printf("str size = %lu\n",sizeof(str)); //打印结果:str size = 4 char charValues[] = { 'b','k','y'};//这个并不是字符串,而是字符数组 printf("charValue size = %lu\n",sizeof(charValues)); //打印结果:charValue size = 3 //占位符%s输出字符串变量,从传入的地址开始,逐个取出字符,知道遇到\0为止 char cc[] = "bokeyuan"; //字符串变量 printf("cc: %s \n", cc); //打印结果: cc: bokeyuan char cc2[] = { 'b', '\0', 'k', 'y'}; //字符数组,%s格式化输出,碰到\0停止 printf("cc2: %s \n", cc2); //打印结果:cc2: b
\0的作用测试
//字符数组的部分初始化, 设置了字符数组的元素个数,然后部分元素初始化,其他元素为默认值0 char cc4[10] = { 'H', 'e', 'l', 'l', 'o'}; //部分初始化,后面默认为0,也就是\0: H e l l o 0 0 0 0 0 printf("cc4地址: %p, 值: %s \n", cc4, cc4); //打印结果:cc4地址: 0x7fff5fbff745, 值: Hello char cc5[] = { 'w', 'o', 'r', '\0'}; //字符数组,以\0结尾 printf("cc5地址: %p, 值: %s \n", cc5, cc5); //打印结果:cc5地址: 0x7fff5fbff721, 值: wor char cc6[] = { 'l', 'd'}; //字符数组,没有以\0结尾,%s输出的时候会一直往上读,一直到碰到\0为止 printf("cc6地址: %p, 值: %s \n", cc6, cc6); //打印结果:cc6地址: 0x7fff5fbff71f, 值: ldwor 为什么字符数组cc6输出的结果是:ldwor , 而不是ld ?
因为%s从输入的地址开始一直往上读数据,直到碰到第一个\0才停止读取。cc6字符数组没有设置\0, 所以一直往上读,一直读到字符数组cc5才碰到了\0停止读取。
excel画图分析说明:

八、字符串常用函数(长度、拷贝、追加、比较)
//字符串常用函数 //1、strlen(str) : 字符串的长度 char ss[] = "博客园bokeyuan"; char ss0[] = "博客园"; size_t strLength = strlen(ss), strLength2 = strlen(ss0); printf("ss长度: %zu, ss0长度:%zu \n", strLength, strLength2); //打印日志:ss长度: 17, ss0长度:9 //2、strcat(s1, s2) 和 strncat(s1, s2, len) : 字符串拼接, 将s2中的数据拼接到s1后面 //要向使用字符串拼接函数,那么s1必须是一个数组,并且数组的长度必须不小于拼接之后的长度\ 如果s1数组的长度, 不能完全存放s+s2+\0 , 那么就会报错 char s1[10] = "hi"; char s2[] = "Hello, World! ^_^"; //strcat(s1, s2); //这种写法运行时会挂,因为s1字符串变量装不了来自s2来的全部数据 //正确拼接方式,先计算源字符串还可以拼接字符的长度 size_t catLen = sizeof(s1) / sizeof(s1[0]) - strlen(s1) - 1; //减去现在的长度和\0 printf("catLen: %zu \n", catLen); //打印日志:catLen: 7 strncat(s1, s2, catLen); printf("拼接后新字符串src: %s \n", s1); //打印日志:拼接后新字符串src: hiHello, //3、strcpy、strncpy :字符串拷贝 char s3[10] = "hi, halo!"; char s3_2[] = "very good ^_^!"; //strcpy(s3, s3_2); //本来是把s3_2的内容拷贝到s3, 并且覆盖掉s3的内容;由于s3_2的内容s3装不下,所以会挂 //所以在拷贝覆盖之前,先计算一下可以存放的长度 size_t s3Len = sizeof(s3) / sizeof(s3[0]) - 1; strncpy(s3, s3_2, s3Len); printf("s3Len: %zu, s3: %s \n", s3Len, s3); //打印日志: s3Len: 9, s3: very good //4、strcmp、strncmp 字符串比较 //取出字符逐个比较,发现不相同则不往下比较,==0表示相同,小于0表示s1小于s2, 大于0表示s1大于s2 char s4[] = "he, hello"; char s4_2[] = "he, nihao"; char s4_3[] = "he, hello"; int s4Result = strcmp(s4, s4_2); //结果是-6, s4小于s4_2 int s4Result2 = strcmp(s4, s4_3); //0, 相等 int s4Result3 = strncmp(s4, s4_2, 3); //比较前面三个字符: 0, 相等 printf("s4Result: %d, s4Result2: %d, s4Result3: %d \n", s4Result, s4Result2, s4Result3); //s4Result: -6, s4Result2: 0, s4Result3: 0